This post is a part of Made @ HubSpot, an internal thought leadership series through which we extract lessons from experiments conducted by our very own HubSpotters.
Have you ever tried to bring your clean laundry upstairs by hand, and things keep falling out of the giant blob of clothing you’re carrying? This is a lot like trying to grow organic website traffic.
Your content calendar is loaded with fresh ideas, but with every web page published, an older page drops in search engine ranking.
Getting SEO traffic is hard, but keeping SEO traffic is a whole other ball game. Content tends to “decay” over time due to new content created by competitors, constantly shifting search engine algorithms, or a myriad of other reasons.
You’re struggling to move the whole site forward, but things keep leaking traffic where you’re not paying attention.
Recently, the two of us (Alex Birkett and Braden Becker 👋) developed a way to find this traffic loss automatically, at scale, and before it even happens.
The Problem With Traffic Growth
At HubSpot, we grow our organic traffic by making two trips up from the laundry room instead of one.
The first trip is with new content, targeting new keywords we don’t rank for yet.
The second trip is with updated content, dedicating a portion of our editorial calendar to finding which content is losing the most traffic — and leads — and reinforcing it with new content and SEO-minded maneuvers that better serve certain keywords. It’s a concept we (and many marketers) have come to call “historical optimization.”
But, there’s a problem with this growth strategy.
As our website’s traffic grows, tracking every single page can be an unruly process. Selecting the right pages to update is even tougher.
Last year, we wondered if there was a way to find blog posts whose organic traffic is merely “at risk” of declining, to diversify our update choices and perhaps make traffic more stable as our blog gets bigger.
Restoring Traffic vs. Protecting Traffic
Before we talk about the absurdity of trying to restore traffic we haven’t lost yet, let’s look at the benefits.
When viewing the performance of one page, declining traffic is easy to spot. For most growth-minded marketers, the downward-pointing traffic trendline is hard to ignore, and there’s nothing quite as satisfying as seeing that trend recover.
But all traffic recovery comes at a cost: Because you can’t know where you’re losing traffic until you’ve lost it, the time between the traffic’s decline, and its recovery, is a sacrifice of leads, demos, free users, subscribers, or some similar metric of growth that comes from your most interested visitors.
You can see that visualized in the organic trend graph below, for an individual blog post. Even with traffic saved, you’ve missed out on opportunities to support your sales efforts downstream.
If you had a way to find and protect (or even increase) the page’s traffic before it needs to be restored, you wouldn’t have to make the sacrifice shown in the image above. The question is: how do we do that?
How to Predict Falling Traffic
To our delight, we didn’t need a crystal ball to predict traffic attrition. What we did need, however, was SEO data that suggests we could see traffic go bye-bye for particular blog posts if something were to continue. (We also needed to write a script that could extract this data for the whole website — more on that in a minute.)
High keyword rankings are what generate organic traffic for a website. Not only that, but the lion’s share of traffic goes to websites fortunate enough to rank on the first page. That traffic reward is all the greater for keywords that receive a particularly high number of searches per month.
If a blog post were to slip off Google’s first page, for that high-volume keyword, it’s toast.
Keeping in mind the relationship between keywords, keyword search volume, ranking position, and organic traffic, we knew this was where we’d see the prelude to a traffic loss.
And luckily, the SEO tools at our disposal can show us that ranking slippage over time:
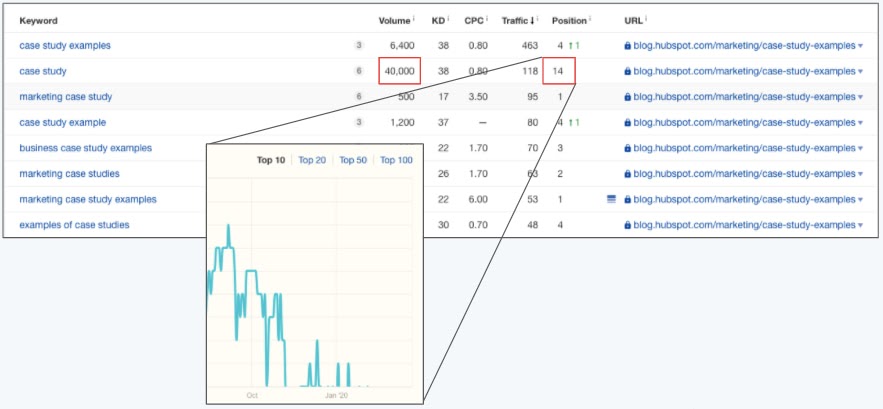
The image above shows a table of keywords for which one single blog post is ranking.
For one of those keywords, this blog post ranks in position 14 (page 1 of Google consists of positions 1-10). The red boxes show that ranking position, as well as the heavy volume of 40,000 monthly searches for this keyword.
Even sadder than this article’s position-14 ranking is how it got there.
As you can see in the teal trendline above, this blog post was once a high-ranking result, but consistently dropped over the next few weeks. The post’s traffic corroborated what we saw — a noticeable dip in organic page views shortly after this post dropped off of page 1 for this keyword.
You can see where this is going … we wanted to detect these ranking drops when they’re on the verge of leaving page 1, and in doing so, restore traffic we were “at risk” of losing. And we wanted to do this automatically, for dozens of blog posts at a time.
The “At Risk” Traffic Tool
The way the At Risk Tool works is actually somewhat simple. We thought of it in three parts:
- Where do we get our input data?
- How do we clean it?
- What are the outputs of that data that allow us to make better decisions when optimizing content?
First, where do we get the data?
1. Keyword Data from SEMRush
What we wanted was keyword research data on a property level. So we want to see all of the keywords that hubspot.com ranks for, particularly blog.hubspot.com, and all associated data that corresponds to those keywords.
Some fields that are valuable to us are our current search engine ranking, our past search engine ranking, the monthly search volume of that keyword, and, potentially, the value (estimated with keyword difficulty, or CPC) of that keyword.
To get this data, we used the SEMrush API (specifically, we use their “Domain Organic Search Keywords” report):
Using R, a popular programming language for statisticians and analytics as well as marketers (specifically, we use the ‘httr’ library to work with APIs), we then pulled the top 10,000 keywords that drive traffic to blog.hubspot.com (as well as our Spanish, German, French, and Portuguese properties). We currently do this once per quarter.
This is a lot of raw data, which is useless by itself. So we have to clean the data and warp it into a format that is useful for us.
Next, how do we actually clean the data and build formulas to give us some answers as to what content to update?
2. Cleaning the Data and Building the Formulas
We do most of the data cleaning in our R script as well. So before our data ever hits another data storage source (whether that be Sheets or a database data table), our data is, for the most part, cleaned and formatted how we want it to.
We do this with a few short lines of code:
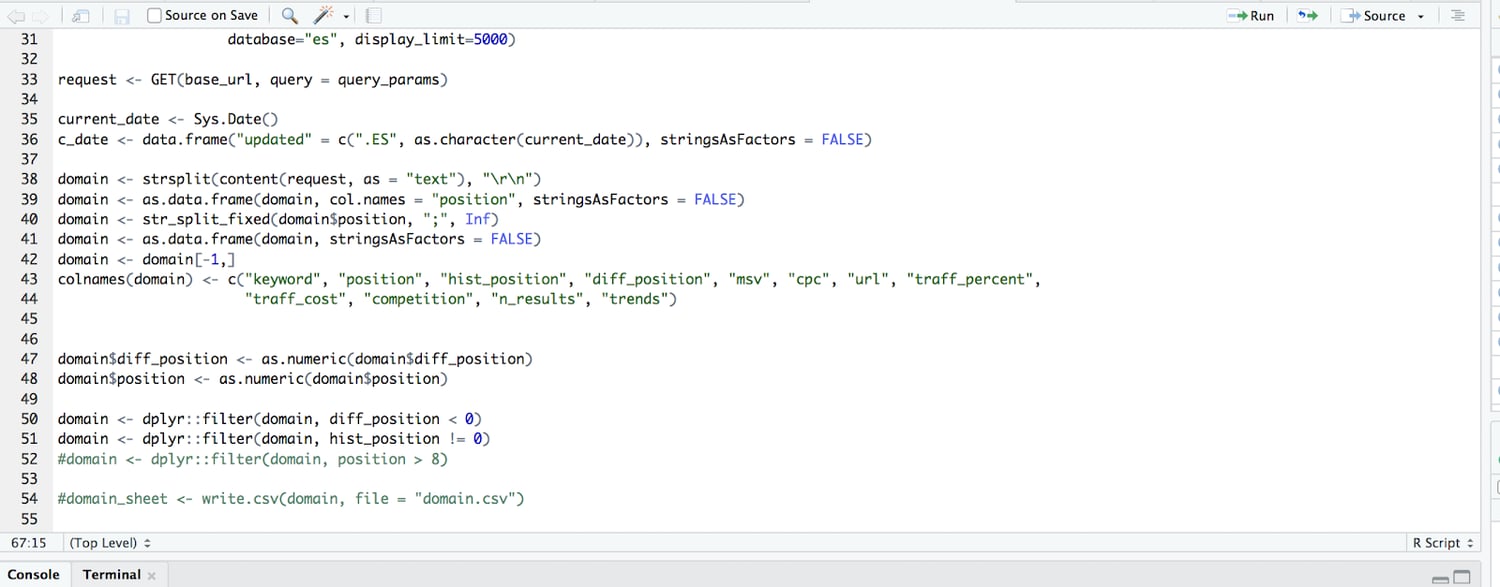
What we’re doing in the code above, after pulling 10,000 rows of keyword data, is parsing it from the API so it’s readable and then building it into a data table. We then subtract the current ranking from the past ranking to get the difference in ranking (so if we used to rank in position 4, and we now rank 9, the difference in ranking is -5).
We further filtered so we only surface those with a difference in ranking of negative value (so only keywords that we’ve lost rankings for, not those that we gained or that remained the same).
We then send this cleaned and filtered data table to Google Sheets where we apply tons of custom formulas and conditional formatting.
Finally, we needed to know: what are the outputs and how do we actually make decisions when optimizing content?
3. At Risk Content Tool Outputs: How We Make Decisions
Given the input columns (keyword, current position, historical position, the difference in position, and the monthly search volume), and the formulas above, we compute a categorical variable for an output.
A URL/row can be one of the following:
- “AT RISK”
- “VOLATILE”
- Blank (no value)
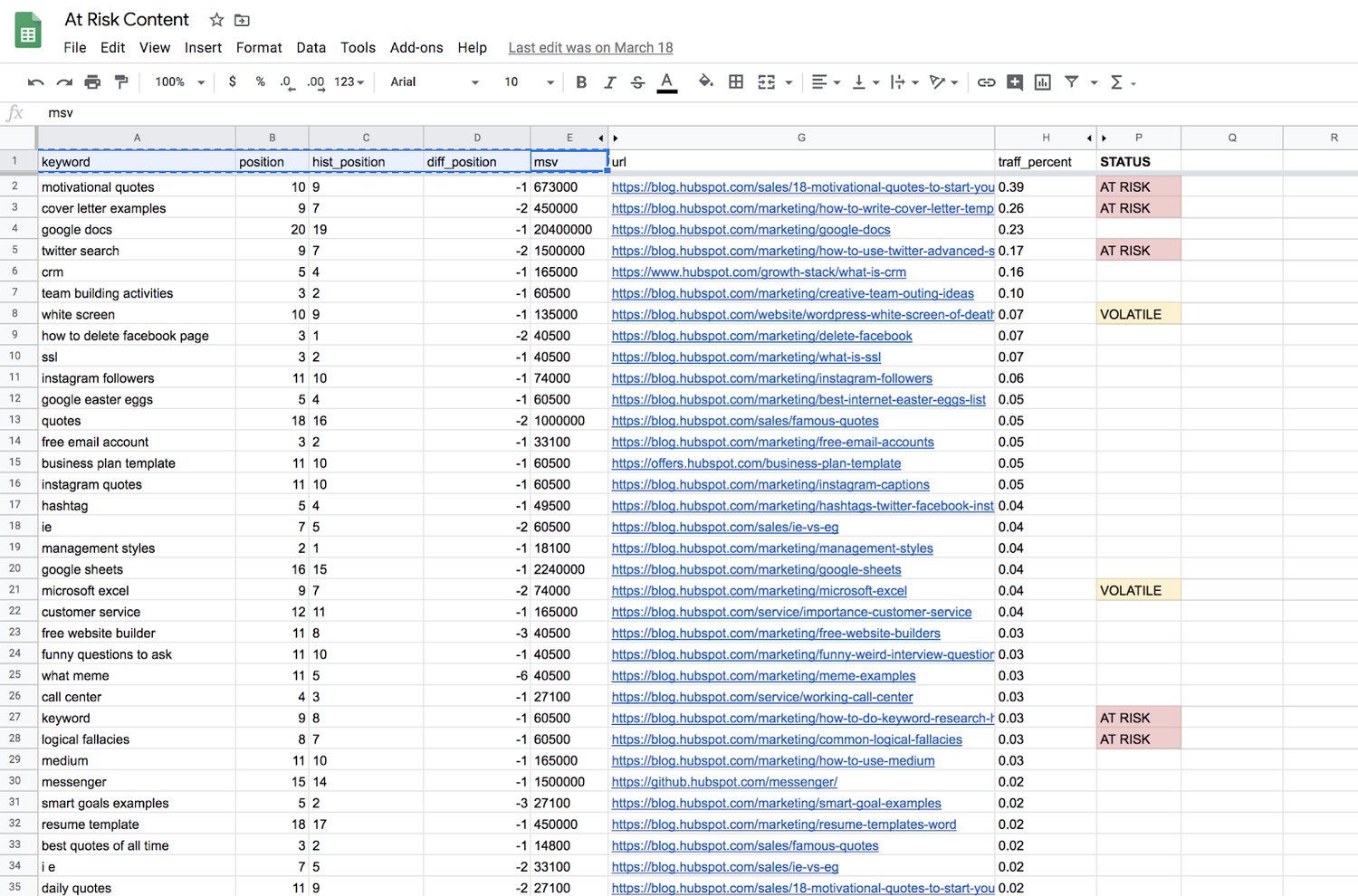
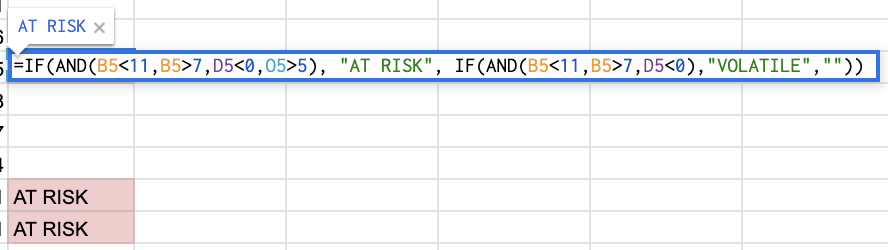
Blank outputs, or those rows with no value, mean that we can essentially ignore those URLs for now. They haven’t lost a significant amount of ranking, or they were already on page 2 of Google.
“Volatile” means the page is dropping in rank, but isn’t an old-enough blog post to warrant any action yet. New web pages jump around in rankings all the time as they get older. At a certain point, they generate enough “topic authority” to stay put for a while, generally speaking. For content supporting a product launch, or an otherwise critical marketing campaign, we might give these posts some TLC as they’re still maturing, so it is worth flagging them.
“At Risk” is mainly what we’re after — blog posts that were published more than six months ago, dropped in ranking, and are now ranking between positions 8 and 10 for a high-volume keyword. We see this as the “red zone” for failing content, where it’s fewer than 3 positions away from dropping from page 1 to page 2 of Google.
The spreadsheet formula for these three tags is below — basically a compound IF statement to find page-1 rankings, a negative ranking difference, and the publish date’s distance from the current day.
What We Learned
In short, it works! The tool described above has been a regular, if not frequent addition to our workflow. However, not all predictive updates save traffic right on time. In the example below, we saw a blog post fall off of page 1 after an update was made, then later return to a higher position.
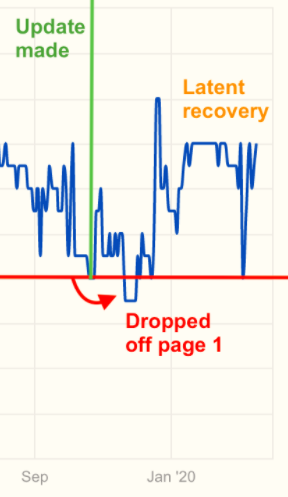
And that’s okay.
We don’t have control over when, and how often, Google decides to recrawl a page and re-rank it.
Of course, you can re-submit the URL to Google and ask them to recrawl (for critical or time-sensitive content, it may be worth this extra step). But the objective is to minimize the amount of time this content underperforms, and stop the bleeding — even if that means leaving the quickness of recovery to chance.
Although you’ll never truly know how many page views, leads, signups, or subscriptions you stand to lose on each page, the precautions you take now will save time you’d otherwise spend trying to pinpoint why your website’s total traffic took a dive last week.
![]()
